 Interactive Demo
Interactive Demo
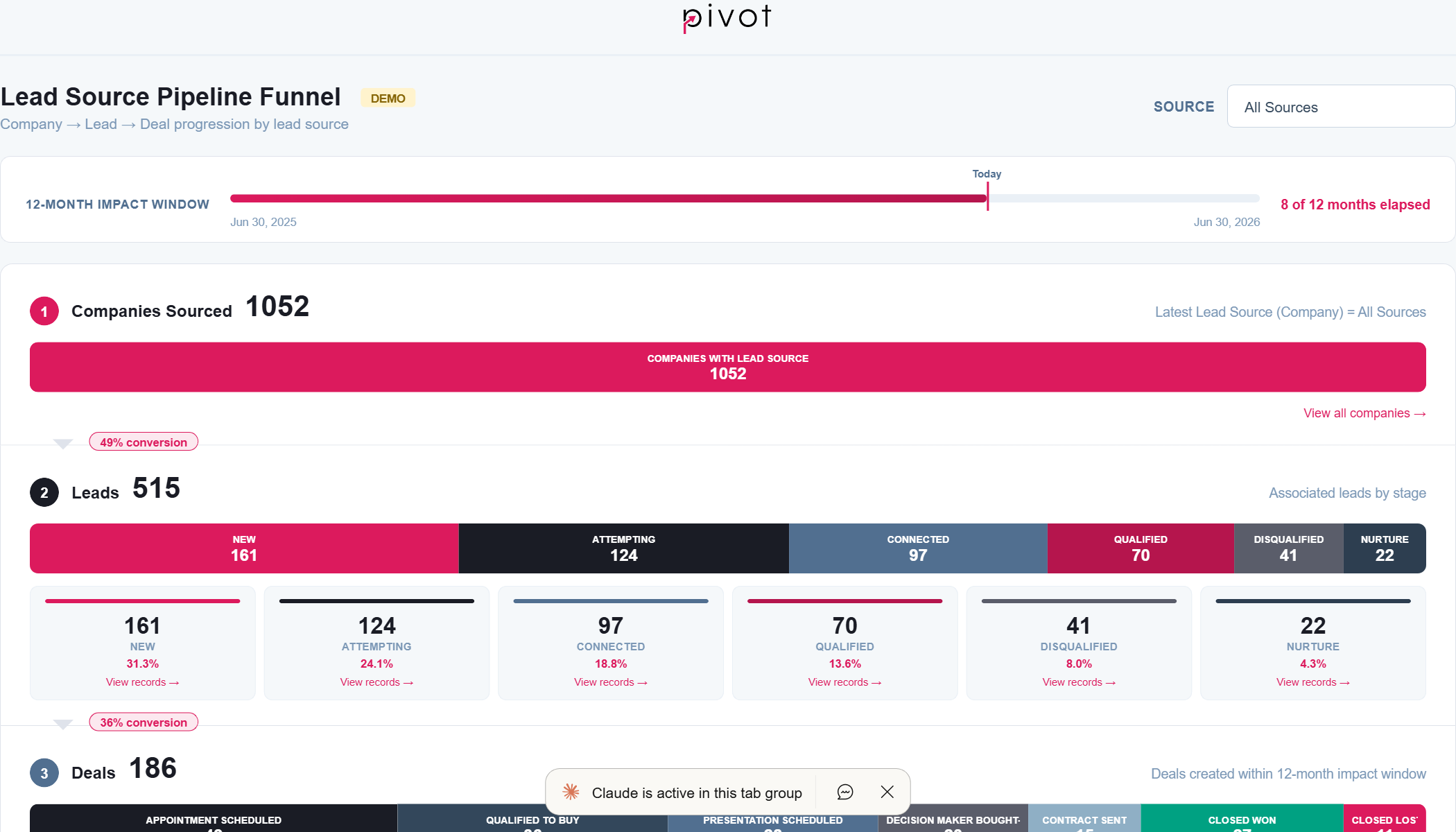
Lead Source Pipeline Funnel
B2B SaaS · Marketing & Sales Alignment
Tracks company-to-lead-to-deal progression by marketing source. Visual funnel with stage-by-stage conversion rates, revenue attribution, and drill-down record tables. Answers: “Which lead sources actually produce closed revenue?”
HubSpot APIs
Cloudflare Worker
Chart.js
Daily Sync
Explore the Demo →
 Interactive Demo
Interactive Demo
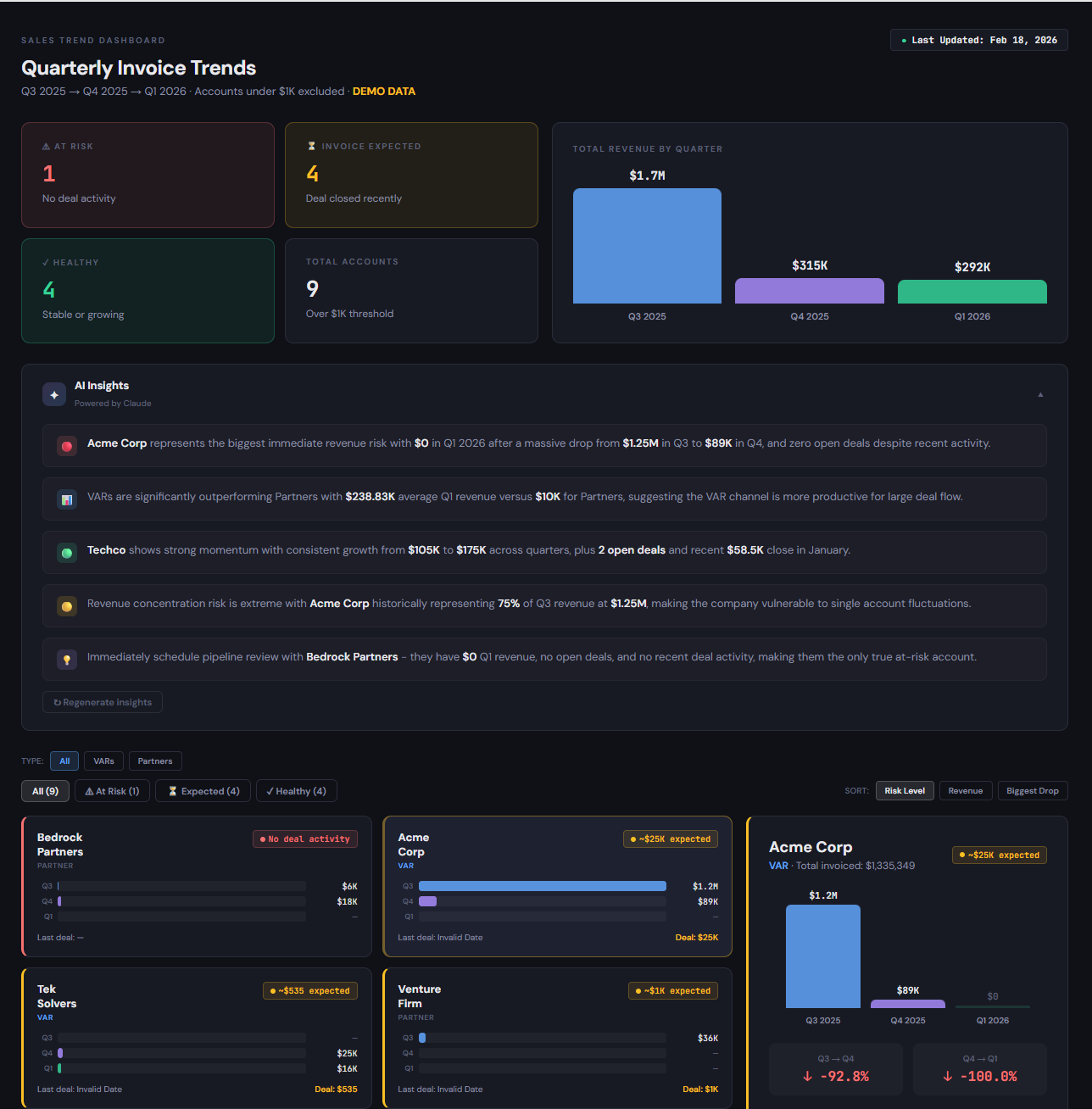
AI-Powered Sales Insights
Manufacturer · At-Risk Account Identification
AI-generated trend analysis flags at-risk accounts 30–60 days early. Visual filtering by date, product, and installer channel. Updates daily via automated HubSpot → Google Sheets → Claude API pipeline. Embedded directly in HubSpot.
Claude API
HubSpot Workflows
Google Sheets API
Chart.js
Explore the Demo →
*Demo reports shown with sample data — actual client data is confidential